Synapse execution plans are specifically for distributed SQL (DSQL) and are not the same as SQL Server execution plans. SQL Server execution plans show the types of join patterns (hash, nested, loop), bookmark lookups, sorts, etc… Whereas Synapse execution plans show you how data must move between the different distributions of a Synapse Dedicated SQL Pool to co-mingle data and complete a query.
A DSQL execution plan is a serial task list which coordinates steps that make calls to each of the 60 distributions which have their own SQL plans. When performance tuning Synapse Dedicated SQL Pools the number one goal is to limit data movement between distributions. Data movement is usually the most costly task in a DSQL plan and therefore the easiest place to make a big performance impact fast. The first step to reviewing the execution plan is to get the execution plan for which there are three methods:
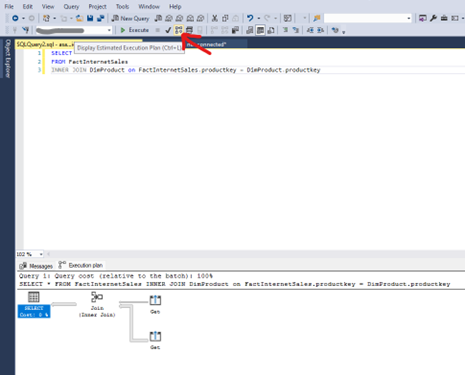
- In SQL Server Management Studio use “Display Estimated Execution Plan” – this is the same as the old SQL methodology of showing the execution plan but for Synapse it shows the distributed SQL plan.
- You can use the keyword “EXPLAIN” before any select statement to show you all of the steps, the fields that datasets are redistributed on, and the estimated cost of each step.

This is the most detailed plan provided but may be limited by your query editor (only 4000 characters returned). The best way around this is to leverage SQLCMD and use the following parameters:
- -i for input file (put your query with the EXPLAIN keyword in a script file)
- -y for variable length type display width
- -o for output of the entire XML plan – this can be really big for complex queries, so it is best to output it to an XML file and review it in a separate text editor.
- After your query has executed you can check the actual query steps in DMV’s:
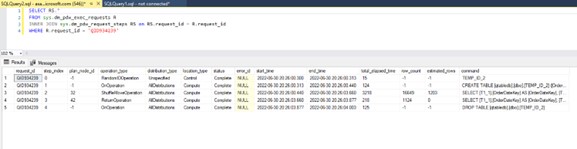
So now we have the dsql execution plan. What does it mean?
There are some immediate red flags to look out for.
- Look at the cost for each operation in the XML plan or the elapsed time for each operation from the sys.dm_pdw_request_steps DMV. The longest running or the most costly operation is where you will want to start. Analyze the estimated number of rows compared to the actual row count of the table involved in the specific data movement operation. If it is drastically wrong, you will want to update statistics so the Optimizer can better determine cost of moving tables and therefore move the smaller of the two datasets to complete the query.
- If you see long running Return operations, it likely indicates one of two issues:
- Indexes are not optimal and therefore the final queries running on individual distributions are working against fragmented indexes. Simply rebuild your index.
- The client application is not able to receive the result set (think aync_network_io from SQL Server) efficiently. This could be due to network, or could be due to memory limitations on the client machine.
The execution plans can tell you much more than just this, but those topics will be covered in later posts as we dig into actual query tuning steps.
![]()